Есть ли ещё куда расти: разбор технологии, финансовый анализ, определение целевой стоимости.
Основы вычислительной техники
Прежде чем перейти к основному содержанию, давайте рассмотрим некоторые фундаментальные технические сведения, которые пригодятся для понимания некоторых моментов в дальнейшем тексте. Не волнуйтесь, мы не будем углубляться в сложные технические детали. Вместо этого объяснения будут даны на качественном уровне, что облегчит понимание концепций, обсуждаемых в следующих разделах. Итак, давайте начнем с введения некоторых ключевых понятий.
Архитектура фон Неймана
Архитектура фон Неймана – это модель архитектуры, которая лежит в основе большинства современных компьютеров. В этой архитектуре компьютер состоит из вычислительного блока, памяти и устройств ввода-вывода. Блок обработки отвечает за обработку данных и выполнение инструкций, а память хранит как данные, так и инструкции. Чтобы выполнить любое вычисление, процессор должен получить инструкции и данные из памяти, а затем сохранить результаты обратно в память.
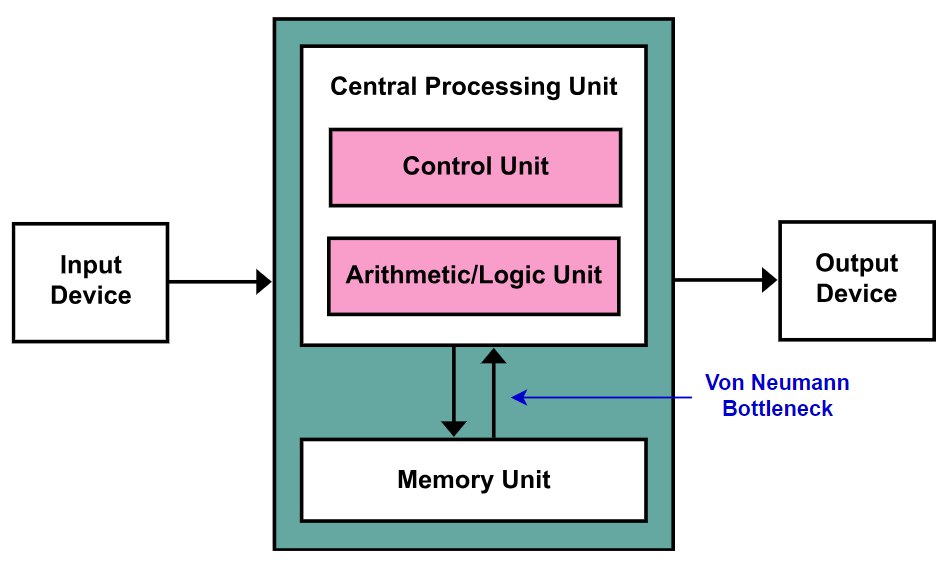
“Узким местом” архитектуры фон Неймана является тот факт, что скорость передачи данных между процессором и памятью намного медленнее по сравнению со скоростью обработки данных процессором. Более того, это “узкое место” становится все более заметным в современных приложениях ИИ. Чтобы понять причину этого, нам нужно немного углубиться в современные большие языковые модели (LLM).
Законы масштабирования в искусственном интеллекте
За последние 50 лет исследований в области ИИ для повышения
производительности алгоритмов ИИ использовались два основных подхода: использование экспертных знаний или использование больших вычислительных мощностей. Исторически сложилось так, что подход, основанный на использовании большего количества вычислений, неизменно имеет преимущество. Эта модель повторяется в различных приложениях, таких как шахматы, игра Go, распознавание речи и других областях. Изначально алгоритмы, использующие экспертные знания, дают хорошие результаты, но позже их превосходят подходы, использующие специализированное оборудование или более высокие вычислительные мощности с более примитивными подходами. Успех подходов, основанных на вычислениях, подчеркивает важность вычислительных ресурсов в расширении границ производительности ИИ, часто отодвигая на второй план роль экспертных знаний.
С реинкарнацией нейронных сетей похожая картина повторяется и в современном ИИ. Большие языковые модели (LLM), такие как GPT-4, сейчас наводняют мир, опираясь на вездесущую архитектуру трансформеров. Эти самые современные модели обучаются на огромных объемах данных, изучая взаимосвязи в языке, что позволяет им отвечать на общие вопросы и выполнять различные задачи с беспрецедентной точностью.
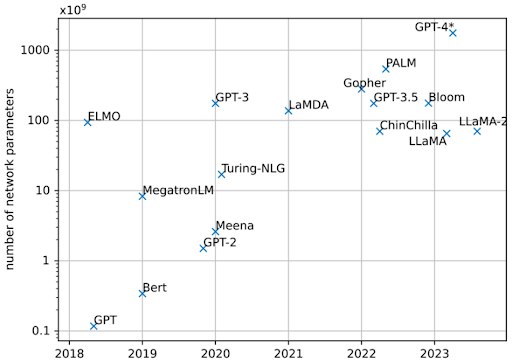
Архитектура трансформеров доказала свою высокую масштабируемость, позволяя LLM достигать превосходной производительности при увеличении объема данных, размера модели и вычислительной мощности. Такая масштабируемость даёт моделям на основе трансформеров значительное преимущество перед другими архитектурами ИИ, повторяя историю, когда подходы, основанные на вычислениях, превосходят методы, основанные на экспертных знаниях. Одним из способов измерения размера сети является количество ее параметров, причем современные сети достигают размера в 1 триллион параметров (см. рисунок выше).
Однако стоимость обучения этих моделей, способных изменить жизнь цивилизации, растет невероятными темпами. Индустрия уже достигла предела возможностей нынешнего оборудования: обучение модели с 1 триллионом параметров обойдется примерно в 300 миллионов долларов при использовании 100 тысяч графических процессоров в течение примерно трех месяцев. Масштабирование до 10 триллионов параметров увеличит стоимость обучения примерно до 30 миллиардов долларов, потребует 1 миллиона графических процессоров и займет более двух лет. Энергопотребление только систем ускорителей и сетей превысит мощность ядерного реактора.
Несмотря на эти проблемы, потенциал для дальнейшего масштабирования сохраняется. На горизонте маячит новое оборудование, а многочисленные стратегии и методы, разработанные в прошлом году, обещают снизить стоимость обучения и обеспечить масштабирование до еще большего числа параметров. Поскольку гонка за создание более крупных и мощных моделей продолжается, очевидно, что для дальнейшего масштабирования моделей необходимо более эффективное оборудование и вычислительные системы.
Проблемы производителей чипов ИИ
Теперь, когда мы затронули тему того, что для обучения и работы современных сетей ИИ требуются быстрые вычислительные мощности и огромное количество взаимосвязанных графических процессоров, давайте обсудим некоторые ограничения для дальнейшего масштабирования нейронных сетей.
Во-первых, для производства самых современных чипов требуется новейший техпроцесс от TSMC, а также передовые “packaging” технологии, такие как CoWoS, мощность которых ограничена, и их мощности полностью раскуплены на ближайшие несколько лет. Во-вторых, как уже говорилось выше, необходимо решить проблему “узкого места” фон Неймана. Пропускная способность памяти на чипе более важна, чем вычислительная мощность самого чипа, что делает «стену памяти» серьезной проблемой. “High Bandwidth Memory” (HBM) – важнейшее решение этой проблемы, причем ее поставки и скорость важнее, чем даже поставки CoWoS сегодня.
Наконец, по мере роста размеров современных нейронных сетей эта проблема становится все более актуальной, поскольку память одного GPU не может вместить всю сеть. Таким образом, современный вычислительный блок – это дата-центр, и огромное количество отдельных чипов должно быть соединено между собой эффективным образом, чтобы оптимизировать стоимость и энергопотребление.
Дорожная карта продукта
Как было объяснено в предыдущем разделе, современные нейронные сети требуют целой экосистемы и не полагаются исключительно на характеристики отдельного чипа. Мы хотели бы выделить три составляющих, принадлежащих Nvidia, и то, как они решают обсуждаемые ограничения:
1. Чипы: Все просто – нужны фундаментальные составляющие.
2. Сетевые технологии: как было объяснено ранее, одного GPU недостаточно для обучения современных моделей корпоративного масштаба, и обычно для построения системы используется большое количество отдельных чипов. Именно здесь в игру вступают сетевые компетенции Nvidia и приобретение в 2019 году компании Mellanox, лидера в области сетевых продуктов.
3. CUDA. И последнее, но не менее важное: для того, чтобы оборудование было полезно для конечных пользователей, требуется программный уровень. Здесь у Nvidia также есть большая фора благодаря своему стеку CUDA.
А теперь давайте перейдем непосредственно к продуктам, анонсированным во время мероприятия GTC 2024.
Суперчип Grace Blackwell
Большинство СМИ сосредоточили свое внимание на анонсе GPU Blackwell. Хотя этот GPU впечатляет и делает значительный скачок со 128 миллиардами дополнительных транзисторов и в четыре раза большим объемом памяти, чем предыдущее поколение GPU Hopper, это не тот “большой” GPU, который стоит выделить. Вместо этого, основное внимание в презентации было уделено GB200, который является огромным улучшением по сравнению с GH200.

GB200 представляет собой сочетание двух GPU Blackwell, подключенных к одному CPU Grace, что снижает стоимость CPU и служит контроллером памяти для GPU. Один GB200 может масштабироваться до дополнительных 480 ГБ памяти. Nvidia идет еще дальше, добавляя два таких вычислительных узла, чтобы получить четыре GPU Blackwell в одном блейд-сервере, и объединяя несколько блейд-серверов в систему. Прежде чем мы перейдем к обсуждению стойки DGX, давайте рассмотрим некоторые сетевые аспекты Nvidia.

NVL72
Люди, которые до сих пор сравнивают Blackwell с Hopper или любыми другими чипами, упускают из виду более широкую картину. Помните, мы обсуждали узкое место пропускной способности памяти и увеличивающийся размер нейронных сетей? Рабочие нагрузки ИИ требуют масштабирования, большие модели ИИ требуют разделения задачи на более мелкие единицы и распределения их по нескольким чипам. GPU, предназначенные для параллельной обработки, до сих пор с трудом справляются с обучением крупнейших моделей на сегодняшний день. Скорость, с которой эти распределенные чипы работают вместе, становится существенным ограничением для общей производительности системы, известным как проблема межсоединений. Как неоднократно подчеркивал генеральный директор Nvidia Дженсен Хуанг, центр обработки данных – это новая единица вычислений. Именно здесь, в системе, и происходит волшебство.
Nvidia анонсировала Infiniband SuperNIC, Bluefield-3 DPU и коммутаторы NVLink следующего поколения. Не вдаваясь в детали каждого продукта, что могло бы стать отдельным постом, мы отметим, что они позволят делать важные выборы оптимизации на уровне системы, что обеспечит гораздо лучшую производительность, чем у конкурентов. Объединяя все это вместе, каждый NV72L будет иметь 72 GPU и станет самым дешевым и при этом самым быстрым сетевым стеком из возможных. Это значительный рывок по сравнению с конкурентами, которые либо не могут предложить такую скорость, либо должны будут сделать это с существенными потерями.
Вся система обеспечивает более одного “exaflop” производительности ИИ, и программное обеспечение рассматривает ее как один гигантский GPU. Это чудо сетевых технологий и один из лучших примеров масштабирования, которые мы когда-либо видели.

В этой новой парадигме сама система подобна чипу, и теперь, если мы рассматриваем систему как новый чип, у нас появляется совершенно новый вектор для масштабирования производительности и мощности.
Программное обеспечение и сервисы
Наконец, мы хотели бы кратко коснуться программной инфраструктуры, которую Nvidia создавала на протяжении последних 10 лет, и новых сервисов, анонсированных во время последней конференции GTC. Одним из наиболее значимых аспектов программной экосистемы Nvidia является CUDA – платформа параллельных вычислений и модель программирования, которая позволяет разработчикам использовать мощь GPU Nvidia для широкого спектра приложений, включая ИИ и машинное обучение. CUDA стала критически важным компонентом в ландшафте разработки ИИ, с обширной библиотекой оптимизированных
инструментов, библиотек и фреймворков, которые позволяют разработчикам эффективно использовать аппаратное обеспечение Nvidia. Эта обширная поддержка программного обеспечения создала значительную платформу для Nvidia, способствующую созданию широкого сообщества разработчиков и сделала GPU Nvidia предпочтительным выбором для многих исследователей и практиков ИИ.
На последней конференции Nvidia GTC компания подчеркнула, что вероятность работы суперкомпьютера в течение недель без перерывов близка к нулю из-за огромного количества компонентов, работающих одновременно. Чтобы решить эту проблему и повысить надежность, Nvidia представила механизм RAS (Reliability, Availability, and Serviceability) – серию систем мониторинга на аппаратном уровне, предназначенных для предотвращения сбоя кластера в течение длительного времени, необходимого для обучения продвинутых моделей, таких как GPT-4.
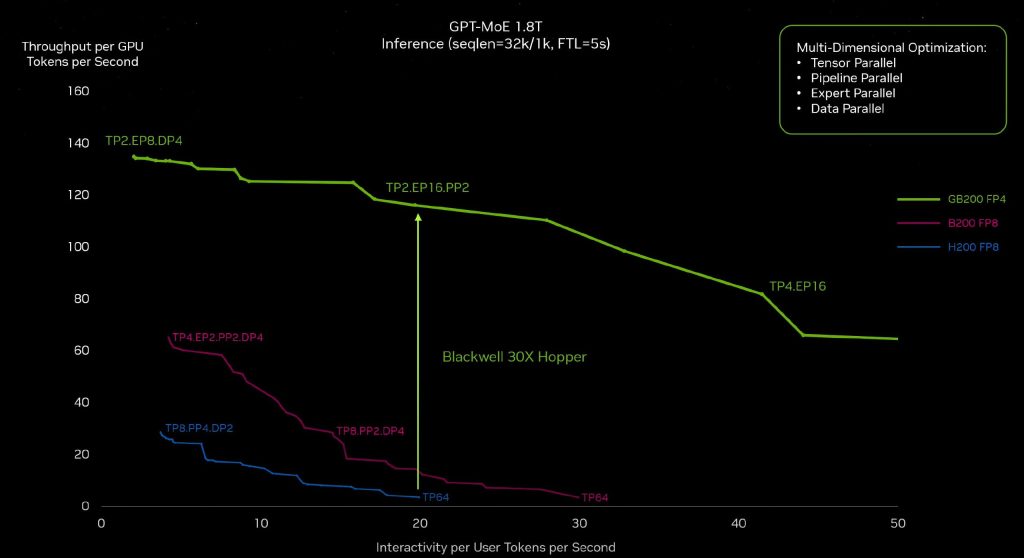
Суммируя улучшения на уровне чипа, сетевых технологий и программного стека, ускорение на системном уровне огромно. Эта оптимизация происходит для каждого типа модели, демонстрируя оптимизацию на системном уровне, которая может быть использована для улучшения вывода общей модели. Это указывает на сложность системы, которую конкурентам вряд ли удастся повторить в ближайшее время. Например, если бы AMD создала MI-400 с большим объемом HBM, она больше не предлагала бы более быстрый или лучший вывод по совокупной стоимости владения, поскольку сеть и межсоединения обеспечивают ускорение вывода выше, чем улучшения на уровне чипа.
Спрос
Затраты от “Big Tech”
Значительная часть спроса на продукцию Nvidia исходит от крупных
технологических компаний, которые конкурируют в гонке вооружений ИИ и строят огромные центры обработки данных для обучения все более крупных моделей. В отчетах о прибылях за прошлый квартал каждая компания из “Большой технологической пятерки” повысила свои прогнозы по капитальным затратам на 2024 год, и большинство из них сделали это существенно.
Meta объявила, что компания ожидает, что ее капитальные затраты за весь 2024 год составят от 35 до 40 миллиардов долларов, увеличившись по сравнению с предыдущим диапазоном от 30 до 37 миллиардов долларов. Учитывая, что в первом квартале было потрачено около 6,4 миллиардов долларов, это подразумевает значительное ускорение в течение года, вероятно, превышая 13 миллиардов долларов в квартал во второй половине года. Это увеличение объясняется ускорением инвестиций в инфраструктуру для поддержки дорожной карты развития ИИ Meta. Хотя прогнозов на период после 2024 года не было, Meta указала, что ожидается продолжение роста капитальных затрат в следующем году, поскольку компания агрессивно инвестирует в свои исследования ИИ и усилия по разработке продуктов.
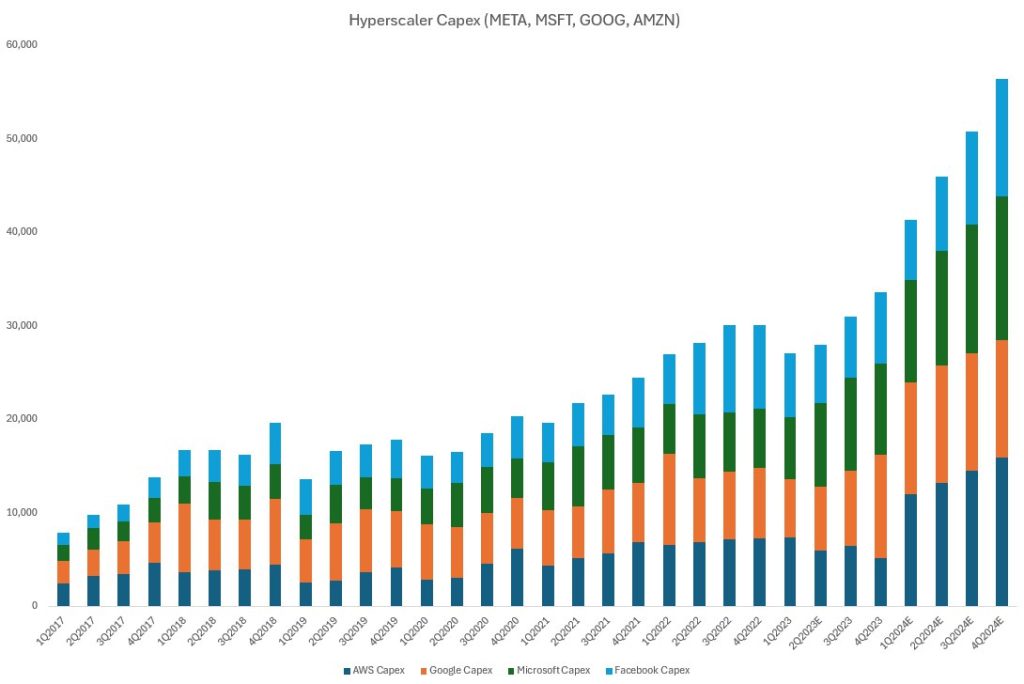
Google сообщила, что капитальные затраты компании в первом квартале составили 12 миллиардов долларов: в основном за счет инвестиций в техническую инфраструктуру. При этом, серверы отмечены самой большой статьей расходов, за которыми следовали центры обработки данных. Существенный рост капитальных затрат в годовом исчислении демонстрирует уверенность Google в возможностях, которые ИИ открывает для их бизнеса. Google ожидает, что ежеквартальные капитальные затраты в течение года будут примерно на уровне или выше уровня первого квартала, что подразумевает общие капитальные затраты примерно в 50 миллиардов долларов за год, что на 55% больше, чем в прошлом году.
Amazon объявила, что компания ожидает значительного увеличения общих капитальных затрат в годовом исчислении в 2024 году. Это увеличение будет в основном обусловлено более высокими капитальными затратами на инфраструктуру для поддержки роста Amazon Web Services (AWS), включая инвестиции в генеративный ИИ. Финансовый директор упомянул, что капитальные затраты Amazon в первом квартале составили 14 миллиардов долларов, и, как ожидается, эта сумма будет расти в течение года.
Microsoft заявила, что компания ожидает значительного последовательного увеличения капитальных затрат, в основном за счет инвестиций в облачную и ИИ-инфраструктуру. Компания продолжает вводить мощности в эксплуатацию для масштабирования своих инвестиций в ИИ в ответ на растущий спрос, который несколько превышает имеющиеся мощности. Microsoft ожидает, что капитальные затраты существенно увеличатся и будут последовательно расти: с ростом на 12% в квартальном исчислении в течение остальной части года, что составит примерно 52 миллиарда долларов. Это представляет собой пятидесяти процентное увеличение капитальных затрат в годовом исчислении за весь календарный год.
Текущая инфраструктура Tesla для обучения ИИ включает около 35 000 GPU от Nvidia, которые используются для обучения последних нейронных сетей компании для системы Full Self Driving (FSD). Во время последнего отчета о прибылях, генеральный директор Илон Маск объявил о планах значительно расширить эти мощности, стремясь увеличить количество GPU до эквивалента примерно 85 тысяч единиц H100. Это существенное увеличение мощности GPU подчеркивает приверженность Tesla к продвижению своей технологии FSD и выделяет растущий спрос на ресурсы высокопроизводительных вычислений в разработке систем
автономного вождения.
Наконец, важно подчеркнуть, что TSMC поделилась информацией о своих мощностях CoWoS, которые, как уже обсуждалось ранее, являются одним из узких мест при производстве чипов для ИИ наряду с памятью HBM. Сообщения от TSMC указывают на то, что из-за повышенного спроса на конечном рынке, Nvidia и AMD полностью забронировали передовые упаковочные мощности TSMC до конца этого года и на весь следующий год. Это подчеркивает значительный спрос на чипы для ИИ, и любой новый игрок, желающий конкурировать в этой области, должен также учитывать, как обеспечить производственные мощности.
Суверенный ИИ
Дженсен Хуанг, генеральный директор Nvidia, недавно представил концепцию “суверенного ИИ” во время дискуссии с министром ИИ ОАЭ на Всемирном саммите правительств в Дубае. Хуанг утверждает, что каждая страна должна контролировать свою собственную инфраструктуру ИИ для защиты своей культуры. В блоге Nvidia далее определила “суверенный ИИ” как владение каждой страной “производством собственного интеллекта”.
Хуанг подчеркнул важность для стран владения своими данными, заявив: “Это кодифицирует вашу культуру, интеллект вашего общества, ваш здравый смысл, вашу историю – вы владеете своими собственными данными”. Это предполагает, что страны должны хранить свои данные в центрах обработки данных в пределах своих собственных географических границ, а не полагаться на облачные сервисы крупных технологических компаний.
ОАЭ – не единственная страна, преследующая эту цель. Многие страны, включая Францию, Японию, Южную Корею и Казахстан, стремятся стать следующим центром силы в области ИИ. Однако создание такой инфраструктуры требует значительных возможностей, которыми обладают лишь несколько стран. В результате, большинству стран потребуется приобрести не только GPU от Nvidia, но и полное решение для центров обработки данных, предоставляемое компанией.

Этот шаг является частью стратегии Nvidia по трансформации в сервисную компанию и устранению посредников, что позволит ей напрямую конкурировать с гигантами индустрии высоких технологий. Важно отметить, что в ближайшие несколько лет это не станет значительной частью дохода Nvidia. Тем не менее, продвигая концепцию “Суверенного ИИ” и предлагая комплексные решения для дата-центров, Nvidia стремится занять лидирующие позиции в мировой индустрии искусственного интеллекта, предоставляя странам возможность сохранять контроль над своей ИИ-инфраструктурой и данными.
Риски
Конкуренты
К этому моменту, надеюсь, стало ясно, что, как неоднократно подчеркивал и сам Дженсен, дата-центр является новой вычислительной единицей. В настоящее время Nvidia превосходит всех по производительности и эффективности, что отражено в заявлении генерального директора Nvidia Дженсена Хуанга о конкуренции: “…наша общая стоимость владения (TCO) настолько хороша, что даже когда чипы конкурентов бесплатны, этого недостаточно…”.
Важно отметить, что каждая другая компания, включая AMD, Broadcom, а также крупные игроки индустрии высоких технологий, пытаются подорвать доминирование Nvidia, однако, благодаря превосходному продукту Nvidia и узким местам в поставках, мы не ожидаем значительной конкуренции до 2026 года.
Риск спроса
По нашему мнению, основной риск исходит со стороны спроса. Действительно, каждый уважающий себя игрок в сфере высоких технологий пытается заполучить GPU от Nvidia. Однако важно помнить, что спрос не бесконечен. Ключевой вопрос заключается в том, как долго создание более крупных нейронных сетей будет приводить к улучшению производительности. Смогут ли в ближайшее время небольшие сети обеспечивать сопоставимую производительность, что приведет к резкому падению спроса на GPU от Nvidia, или же крупные игроки продолжат гонку вооружений, создавая все более крупные сети и закупая еще больше GPU от Nvidia?
Хотя мы считаем спрос основным риском, исходя из нашего текущего анализа, мы ожидаем, что спрос на продукцию Nvidia будет превышать предложение в течение 2024-2025 годов.
Другие риски
Мы хотели бы отметить, что всегда существуют риски, связанные с
геополитической ситуацией, серьезными экономическими спадами и другими непредвиденными событиями. Хотя эти риски могут оказать значительное влияние на бизнес и отрасли, мы не будем здесь углубляться в их анализ.
Квартальный отчет
Все ожидают, что Nvidia превзойдет ожидания и повысит прогнозы. На этот квартал Дженсен Хуанг пообещал последовательный рост выручки примерно на 9% при операционной марже около 65%.
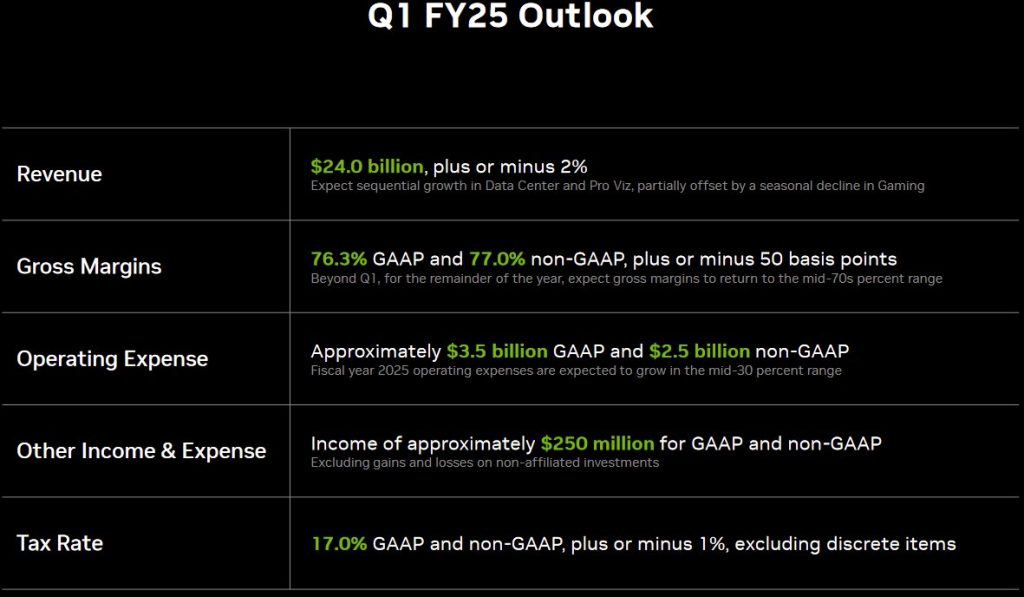
Мы ожидаем, что Nvidia действительно превзойдет ожидания и повысит прогнозы на ближайшие пару кварталов, после чего нам нужно будет подготовиться к диверсификации нашего портфеля, чтобы продолжать извлекать выгоду из революции в области ИИ (например, в области HBM (памяти), ПО для ИИ, периферийного ИИ и т.д.).
Анализ денежных потоков
У Nvidia были впечатляющие показатели операционной маржи денежных потоков, превышающие 40%, и быстро растущий свободный денежный поток (FCF) в прошлом году. Однако, на основе данных за последние двенадцать месяцев, FCF Nvidia все еще в четыре раза меньше, чем у Apple, хотя рыночная капитализация Nvidia “всего лишь” на 30% меньше, чем у Apple, и почти такая же, как у Alphabet.
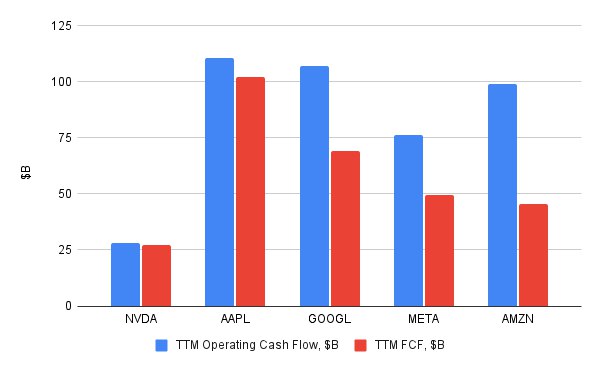
Прогнозируя выручку на 2025 год и придерживаясь консервативного прогноза с 15% ростом (по мере насыщения спроса), 50% маржой прибыли, 2,5 миллиардами акций в обращении и терминальным P/E 30, мы рассчитываем цену акции в 2025 году на уровне $1144. Это говорит о том, что у акций все еще есть потенциал роста на 20% от сегодняшнего уровня ($950 за акцию). Однако мы считаем, что акции превзойдут эти ожидания, особенно после преодоления долгосрочного психологического сопротивления в $1000 за акцию.
Технический анализ
Мы не используем технический анализ для обоснования нашего тезиса, а скорее пытаемся найти объективные закономерности, подтверждающие его. С точки зрения паттернов движения цены акций, мы видим два положительных индикатора.
1. Сужение волатильности (серая линия) – бычий индикатор в случае
положительного отчета о прибыли.
2. Потенциальный паттерн волн Эллиотта (синяя линия) – с самой длинной волной (2) -> (3), обеспечивающей лучшие возможности для получения прибыли.
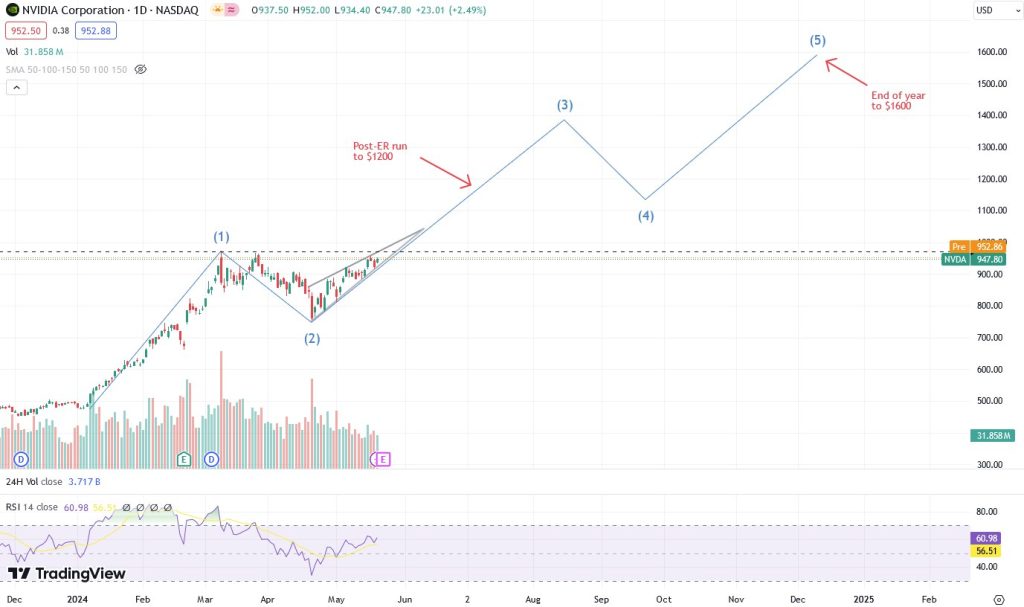
Технический анализ говорит, что в ближайшие месяцы возможен рост до $1200, и до $1600 к концу года. Мы считаем что этот тезис будет опровергнут, если мы не преодолеем текущий уровень сопротивления $975 (пунктирная линия) – т.е. если мы развернемся и точка (3) окажется ниже точки (1). Однако, мы считаем, что превышение ожиданий и повышение прогнозов в предстоящем отчете о прибыли придаст акциям необходимый импульс для преодоления психологического барьера в $1000 за акцию и дальнейшего роста.
Заключение
Nvidia, несомненно, доминирует над конкурентами, и ее последний GTC от Nvidia только подтвердила этот факт. Сетевые технологии компании ставят ее на целое поколение впереди таких конкурентов, как Broadcom и AMD. Крайне важно понимать, что Nvidia продает не просто чип, а полноценную систему. Путать одно с другим – значит полностью упустить суть.
Реалистично, наш целевой уровень цены акций после публикации отчета о прибыли составляет $1000+, исходя из ожидаемых денежных потоков в 2025 году. К концу года мы ожидаем $1200, если Nvidia продолжит превосходить ожидания и поддерживать расширенный мультипликатор.
Список литературы
- https://www.fabricatedknowledge.com/p/jensens-world-compressing-reality-be4
- https://www.semianalysis.com/p/the-ai-brick-wall-a-practical-limit
- https://www.researchgate.net/figure/Number-of-parameters-of-LLM-over-the-past-five-years-Significant-advances-were-made-by_fig1_377469845
- https://en.wikipedia.org/wiki/Von_Neumann_architecture
- https://developer.nvidia.com/blog/nvidia-gb200-nvl72-delivers-trillion-parameter-llm-training-and-real-time-inference/
- http://www.incompleteideas.net/IncIdeas/BitterLesson.html
- https://nvidianews.nvidia.com/news/oracle-nvidia-sovereign-ai
После выхода квартального отчета мы подготовим пост с обзором основных моментов. Подписывайтесь на канал, чтобы не пропустить новые посты.